针对某一个搜狐号,进入其主页,进行采集,该主页网址无法采集到列表,不能采集到列表也就没法进行批量采集,所以,首先要解决该问题。
其次,搜狐自媒体号上的文章URL都有一定的特点,如下:
http://www.sohu.com/a/变量
我们只需要把这个变量找到就好了!然后用火车头拼接一下URL就可以了。
难点:抓包找数据分析
案例如下:
1、目标搜狐号主页:http://mp.sohu.com/profile?xpt=cHBhZzc5Mjg1OTg1MDkxNEBzb2h1LmNvbQ==&_f=index_pagemp_1
2、fiddler抓包,如下图所示:
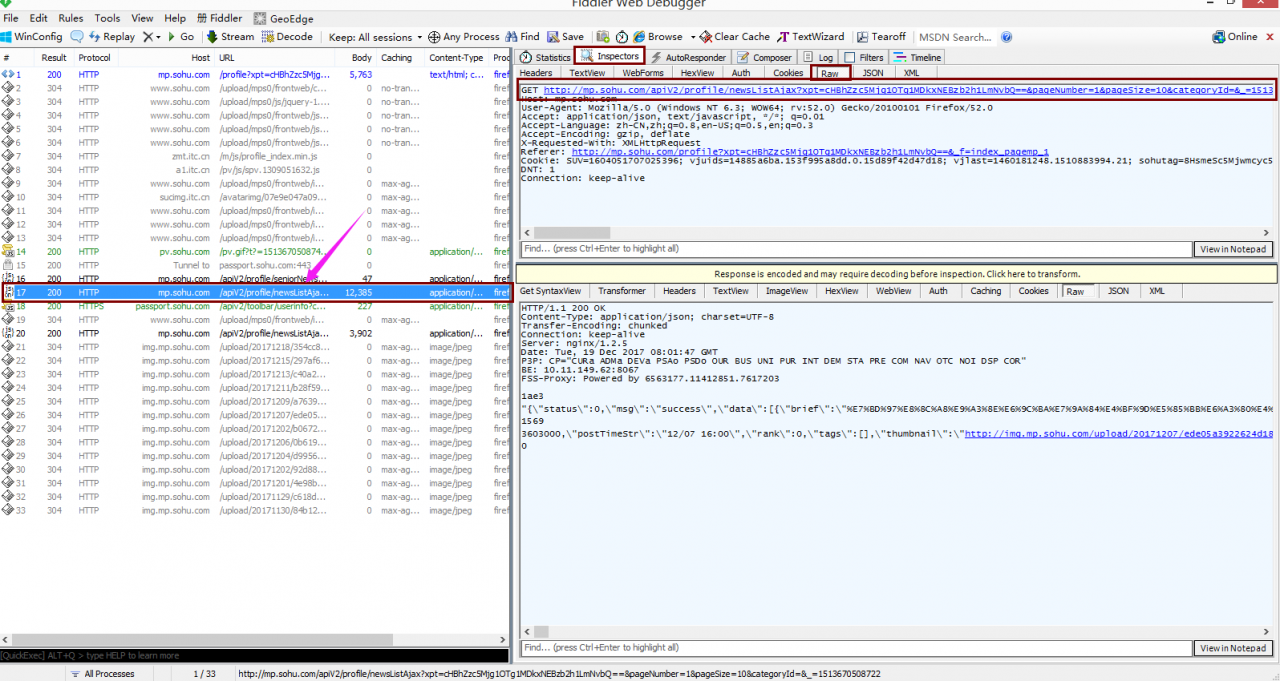
查看大图
该网址就是列表url原来的地址: http://mp.sohu.com/apiV2/profile/newsListAjax?xpt=cHBhZzc5Mjg1OTg1MDkxNEBzb2h1LmNvbQ==&pageNumber=1&pageSize=10&categoryId=&_=1513670508722
在火车头中多页采集修改这个地方:pageNumber=1
3、采集文章页URL
把上面的原址用浏览器打开,如下图所示:

我们把黑色圈中的部分采集下来即可。然后火车头采集规则这么编写:
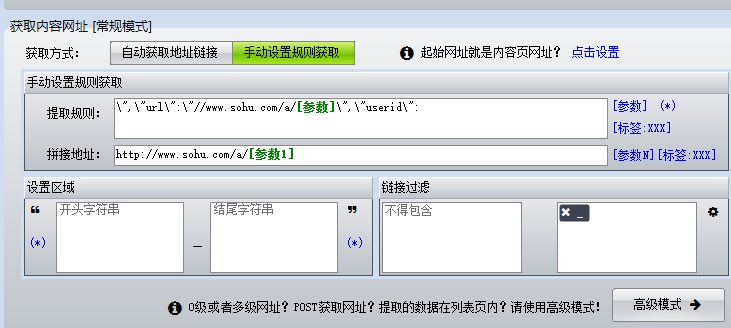
列表页采集到了,内页文章页可以直接看源码编写采集规则,上面是难点,简单的就不啰嗦了。
评论前必须登录!
注册